Earlier Experiments
These are older builds, but they still show useful instincts around product framing, interface design, and
turning loose ideas into something testable.
Local Poach
Browser-extension concept that aimed to promote local food businesses over dominant chains using
search-context signals and location-aware recommendations.
Ecoswap
A recommendation concept for artisan alternatives during shopping flows using visual parsing and
marketplace search integration.
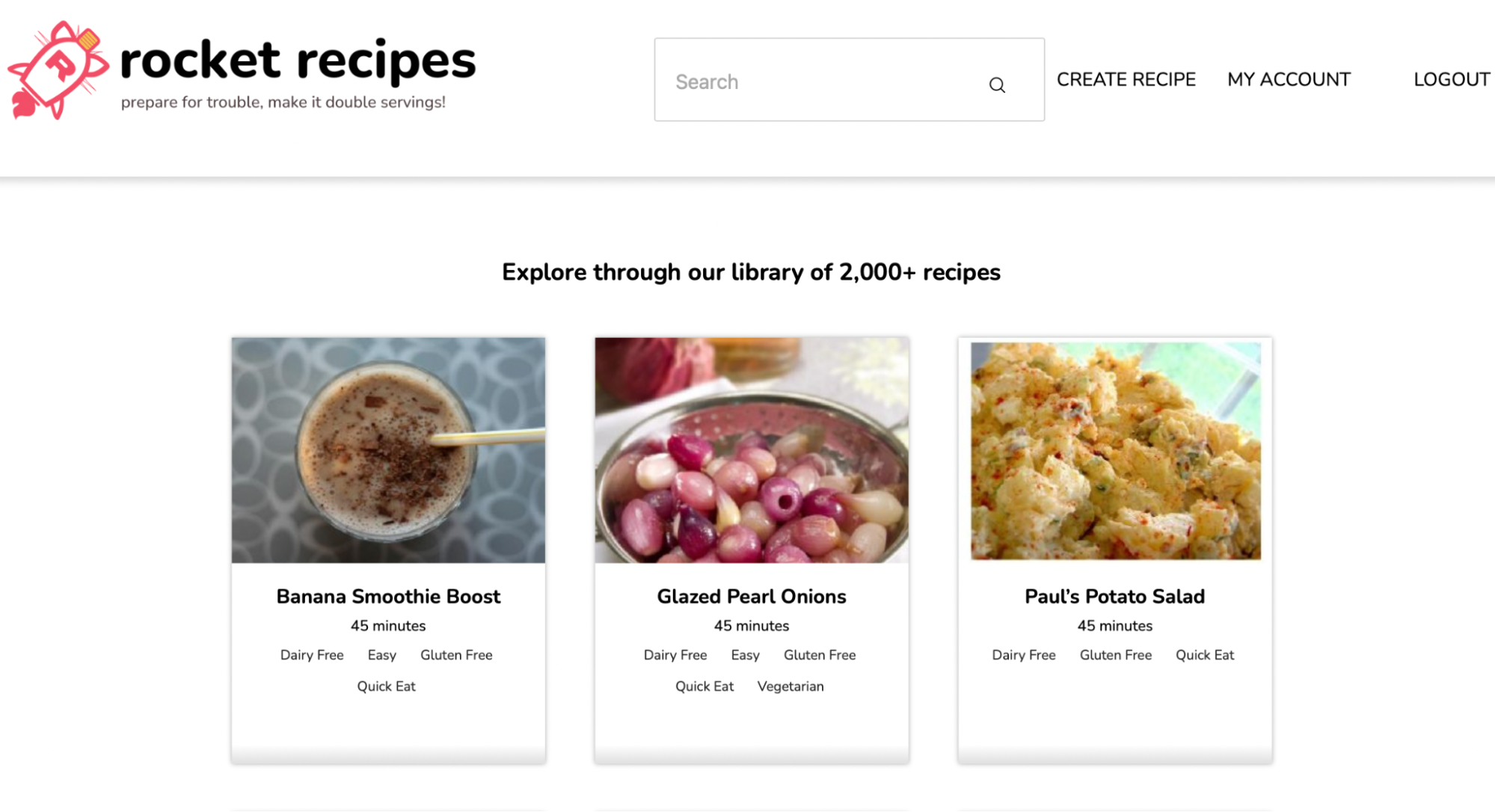
Rocket Recipes
Collaborative CRUD app for recipe management with Firebase persistence, built with project-planning and
stakeholder-style workflows.
Selected System Work
A few examples of the larger-system thinking behind the product pages above: enforcement paths, signal models,
stream processing, documentation surfaces, and automation layers.
Direct Ban Endpoint
Operational path to apply focused enforcement actions without waiting on a full automated cycle.
Event Processing with Flink
Early stream-processing groundwork for handling event context and reducing false positives.
Documentation Modernization
Introduced a docs surface that improved readability while preserving existing markdown workflows.
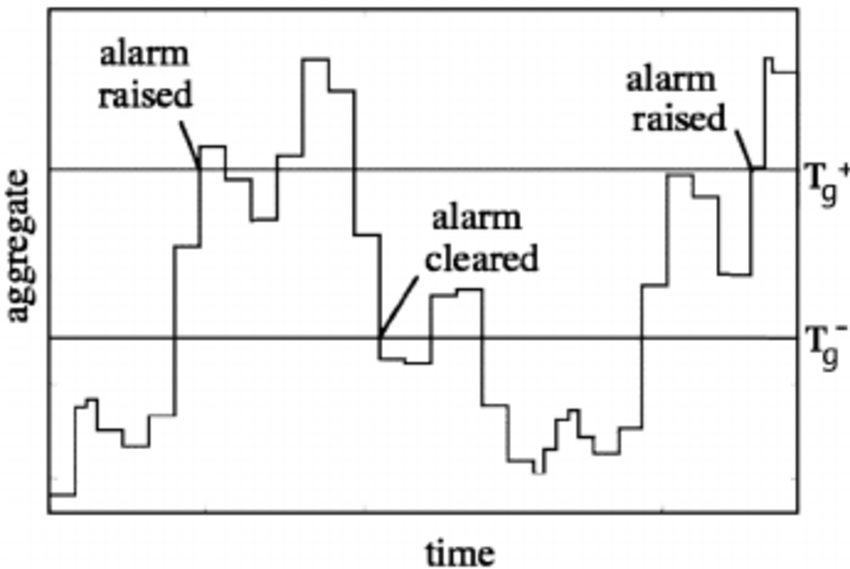
Automated Threshold Flow
Pipeline concepts for syncing threshold updates with reduced manual handoff overhead.
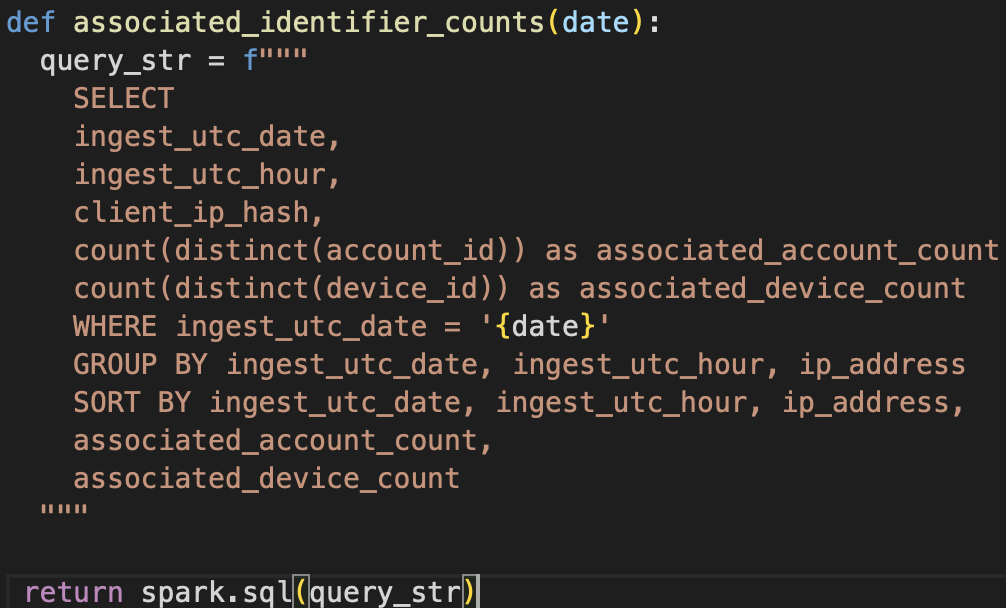
Associated Identifiers
Expanded signal context by evaluating account-device and account-network relationships.
IPv6 Subnet Handling
Refined policy logic for interface-identifier evasion patterns and subnet-level escalation.